
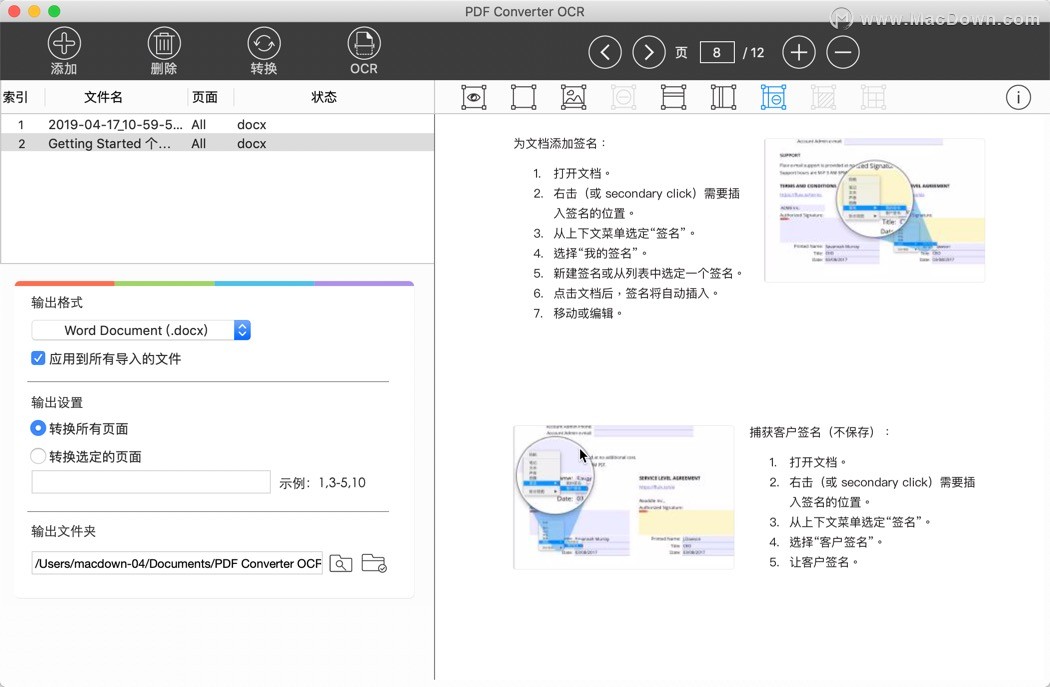
PDF Converter OCR Mac版是一款具有助于访问扫描的PDF,编辑PDF,支持多选择输出格式,并保持100%的原始布局,精准的将PDF和图像转换为Word,文本,PPT,主题词,页面等功能。PDF文档(可移植文档格式)可以从各种来源和不同的设备或软件创建,因此它们并不总是相同。扫描PDF是一个典型示例,有时它看起来像是从Word创建的普通PDF文件,但实际上当您使用扫描仪扫描纸张时,整个内容将被捕获为图像。因此,当您将其另存为PDF文件时,没有文本内容,只有PDF文件中嵌入的图像。
在这种情况下,如果要将扫描的PDF转换为可编辑和可搜索的Word文档,则需要选择正确的PDF转换器。需要光学字符识别(OCR)来识别和提取图像中的数据。
但是,我们如何区分扫描的PDF和普通文件?有时它们看起来就像是一样的东西。以下是一些方法:
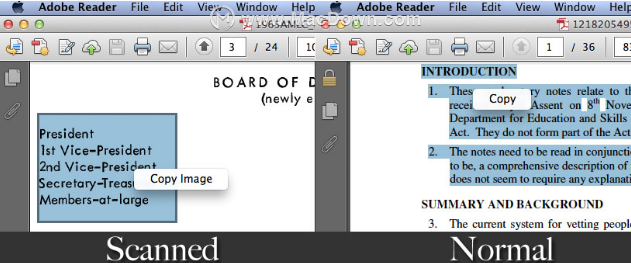
1.选择文本
您无法从扫描的PDF中选择任何文本,只能选择图像区域。但您可以从普通PDF中选择和复制文本。
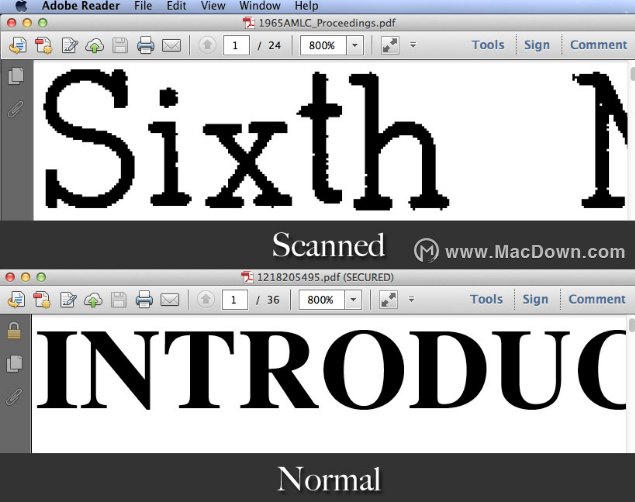
2.放大
尝试放大PDF文件,扫描的PDF中的内容将模糊和像素化。但是在普通的PDF文件中,即使将文档放大到广告牌大小,文本也可以保持相同的清晰质量。
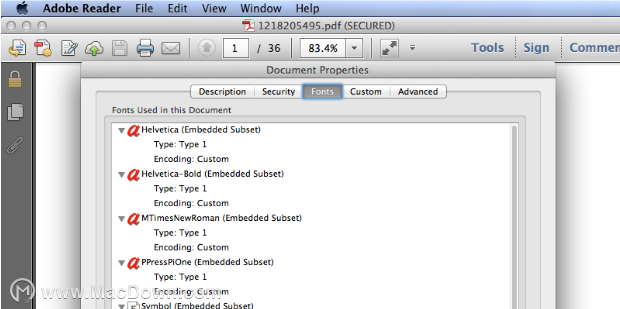
3.检查文档属性
如果在Adobe Reader中打开扫描的PDF,您将看到文档属性中没有字体信息。PDF没有OCR功能的转换器无法识别扫描的PDF文件中的文本,因此它们只能输出图像而不是可编辑的内容。
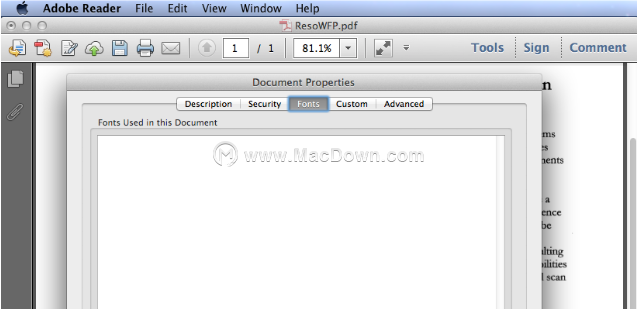
但是,如果使用文本数据打开普通PDF,则可以在“文档属性”中找到本文档中使用的字体。
以上内容便是使用PDF Converter OCR for Mac如何区分扫描的PDF和普通文件的方法,如需了解更多mac软件教程敬请关注本站。