
Screaming Frog SEO Spider for Mac是一个网站爬虫,允许你抓取网站的网址,并获取关键要素,分析和审计技术和现场搜索引擎优化。在本篇文章中,我们介绍的是Screaming Frog SEO Spider for Mac进行网页抓取和数据提取的技巧。
Screaming Frog SEO Spider for Mac使用教程
1)点击“配置>自定义>提取”
该菜单可以在SEO Spider的顶级菜单中找到。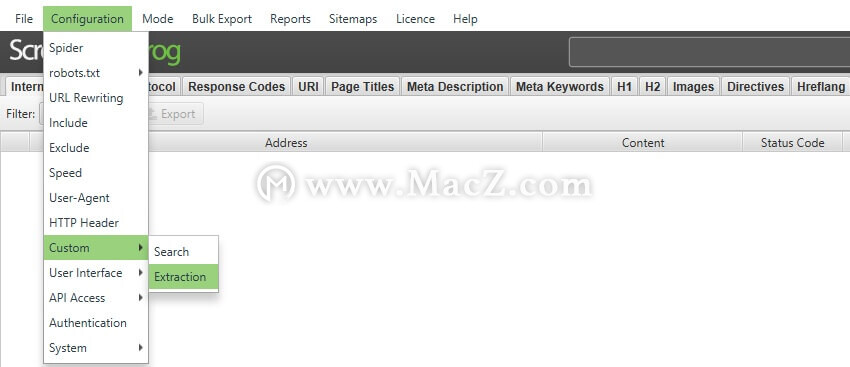 自定义提取以进行网页抓取
自定义提取以进行网页抓取
这将打开自定义提取配置,允许您配置多达100个单独的“提取器”。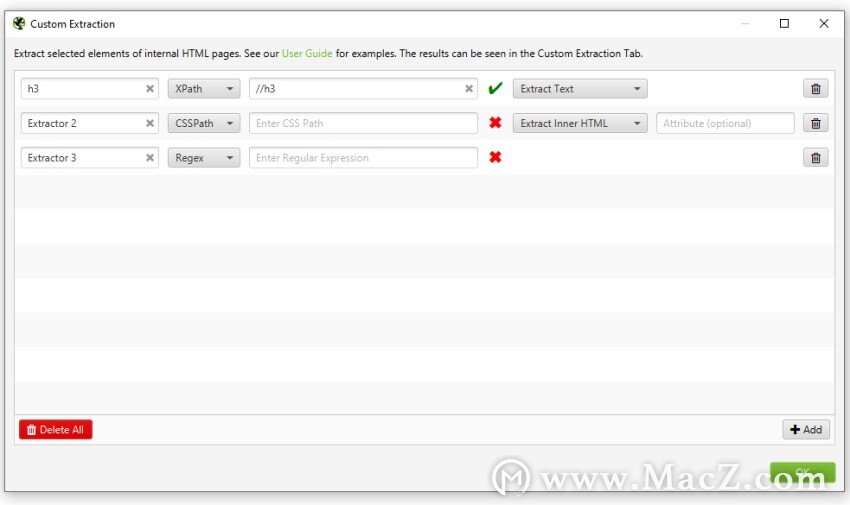 2)选择CSS路径,XPath或正则表达式进行剪贴
2)选择CSS路径,XPath或正则表达式进行剪贴
在尖叫青蛙 SEO蜘蛛工具提供从网站抄袭数据的三种方法:
XPath – XPath是一种查询语言,用于从XML之类的文档(例如HTML)中选择节点。此选项使您可以使用XPath选择器(包括属性)来抓取数据。
CSS路径 –在CSS中,选择器是用于选择元素的模式,通常是三种可用方法中最快的一种。此选项使您可以使用CSS路径选择器来抓取数据。可选属性字段也可用。
正则表达式 –正则表达式当然是用于匹配数据模式的特殊文本字符串。这最适合高级用途,例如抓取HTML注释或内联JavaScript。
建议在大多数常见情况下使用CSS Path或XPath,尽管它们都有各自的优势,但是您可以简单地选择最适合使用的选项。
使用XPath或CSS Path收集HTML时,您可以使用下拉过滤器准确选择要提取的内容–
提取HTML元素 –所选元素及其所有内部HTML内容。
提取内部HTML –所选元素的内部HTML内容。如果所选元素包含其他HTML元素,则将它们包括在内。
提取文本 –所选元素的文本内容以及任何子元素的文本内容。
3)输入语法
接下来,您需要将语法输入到相关的提取器字段中。查找要抓取的数据的相关CSS路径或Xpath的快速简便方法是,只需在Chrome中打开网页,然后打开要收集的HTML行的“检查元素”,然后右键单击并复制提供的相关选择器路径。
例如,您可能希望开始抓取博客文章的“作者”,并且每个人都收到了评论。让我们以Screaming Frog网站为例。
在Chrome中打开任何博客帖子,右键单击并在每个帖子上的作者姓名上单击“检查元素”,这将打开“元素” HTML窗口。只需再次右键单击相关的HTML行(具有作者姓名),复制相关的CSS路径或XPath,然后将其粘贴到SEO Spider的相应提取器字段中即可。如果您使用Firefox,则也可以在其中进行相同的操作。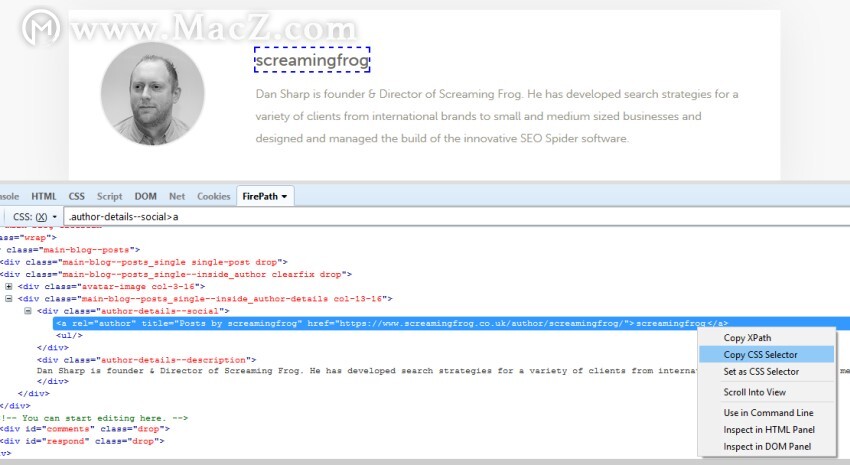 CSS Path Scraping作者您可以重命名“提取程序”,它对应于SEO Spider中的列名。在此示例中,我使用了CSS Path。
CSS Path Scraping作者您可以重命名“提取程序”,它对应于SEO Spider中的列名。在此示例中,我使用了CSS Path。 定制提取作者和评论
定制提取作者和评论
每个提取器旁边的对勾确认所使用的语法有效。如果它们旁边有一个红叉,则可能需要进行一些调整,因为它们无效。
当您感到高兴时,只需按下底部的“确定”按钮即可。如果您想查看更多示例,请跳至本指南的底部。
请注意–这不是构建CSS选择器和XPath表达式的最可靠的方法。使用此方法给出的表达式可以非常特定于元素在代码中的确切位置。由于检查的视图是页面/ DOM的呈现版本,因此这是可以更改的,默认情况下,SEO Spider会查看HTML源代码,而SEO Spider在其中处理页面时会进行HTML清理是无效的加价。
这些内容在浏览器之间也可能有所不同,例如,对于上述“作者”示例,给出了以下CSS选择器–
Chrome:正文> div.mAIn-blog.clearfix> div> div.mAIn-blog-posts> div.mAIn-blog-posts_single-inside_author.clearfix.drop> div.mAIn-blog-posts_single-inside_author-detAIls.col- 13-16> div.author-detAIls-social>
Firefox: .author-detAIls-social> a:nth-child(1)
Firefox提供的表达式通常比Chrome提供的表达式更强大。即使这样,也不应将其用作理解各种提取选项并能够通过检查HTML源代码手动构建这些选项的完整替代。
关于CSS选择器的w3schools指南及其XPath简介是了解这些表达式基础的好资源。
4)抓取网站
接下来,在顶部的URL字段中输入网站地址,然后单击“开始”以爬网网站并开始抓取。 5)在“自定义提取”选项卡下查看爬取的数据
5)在“自定义提取”选项卡下查看爬取的数据
抓取的数据开始在抓取过程中实时显示在“自定义提取”选项卡以及“内部”选项卡下,您可以将收集到的所有数据一起导出到Excel中。
在上面概述的示例中,我们可以看到每篇博客文章旁边的作者姓名和评论数已被抓取。
自定义提取
当进度条达到“ 100%”时,爬网已完成,您可以选择使用“导出”按钮来“导出”数据。
如果您已经有了想要从中提取数据的URL列表,而不是抓取网站来收集数据,则可以使用列表模式上载它们。
而已!希望以上指南有助于说明如何使用SEO Spider软件进行网页抓取。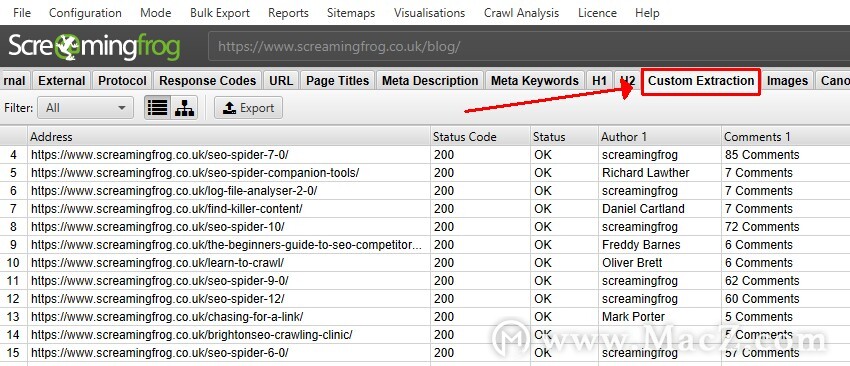
显然,可能性是无限的,此功能可用于收集任何内容,从纯文本到Google Analytics(分析)ID,架构,社交元标签(例如Open Graph标签和Twitter卡),移动注释,hreflang值以及价格产品,折扣率,库存可用性等。我已经介绍了更多示例,这些示例按提取方法划分。
以上就是今天Macz为大家介绍的Screaming Frog SEO Spider for Mac进行网页抓取和数据提取的技巧,希望对您有所帮助。