
Screaming Frog SEO Spider已经推出好久,历经多次更新,很多用户都在使用,作为其中一个用户,你对Screaming Frog SEO Spider的了解有多少呢?Screaming Frog SEO Spider的11个鲜为人知的功能你用过几个?下面我们一起来看看吧。
1)以相同的顺序导出列表
如果您已将网址列表上传到SEO Spider中,执行了抓取并希望以上传时的顺序导出它们,请使用“上传”和“开始”按钮旁边的“导出”按钮在用户界面的顶部。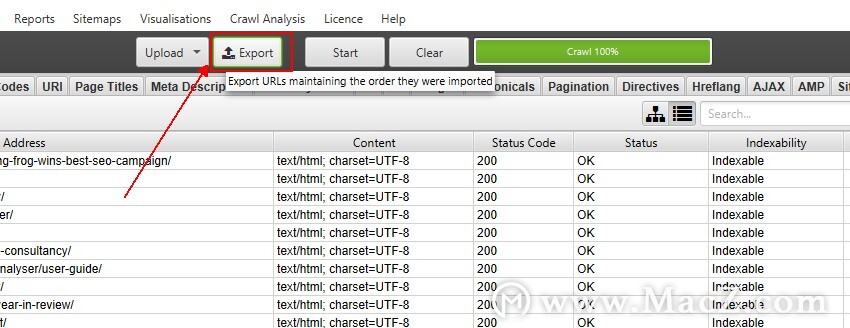
否则,仪表板上的标准导出按钮将根据首先抓取的内容以及内部的标准化方式按顺序导出URL(在通常不采用广度优先的蜘蛛模式的多线程抓取工具中,URL看起来非常随机) )。
导出中的数据将以完全相同的顺序进行,并包括原始上传文件中的所有确切URL,包括重复项,规范化或执行的任何修正。
2)抓取在Google Analytics(分析)和Search Console中发现的新网址
如果您通过API连接到Google Analytics(分析)或Search Console,默认情况下,发现的所有新URL不会自动添加到队列中并进行爬网。加载了URL,将数据与爬网中的URL进行了匹配,并且任何孤立URL(仅在GA或GSC中发现的URL)都可以通过“孤立页面”报告导出获得。
如果您希望将自动发现的所有URL添加到队列中,对其进行爬网并在界面中查看它们,只需启用“对在Google Analytics /搜索控制台中发现的新URL进行爬网”配置。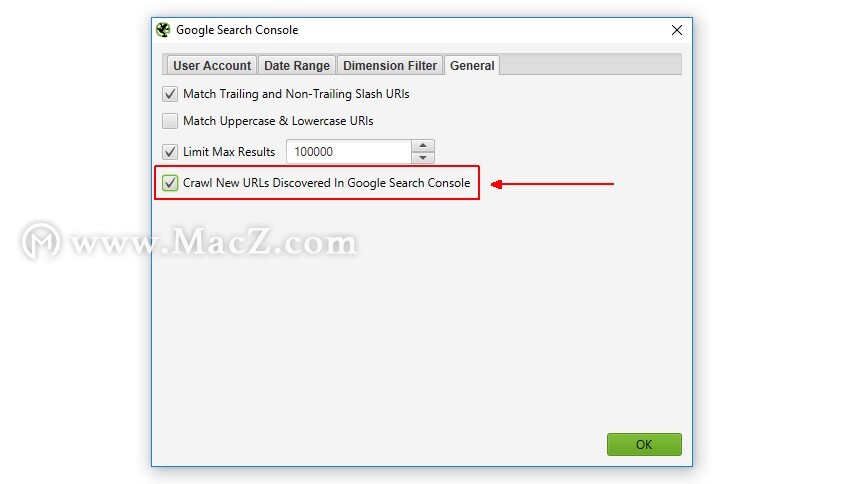
可在“配置> API访问”下,然后在“ Google Analytics(分析)”或“ Google Search Console”(Google搜索控制台)及其各自的“常规”标签下使用。
这意味着发现的新URL将出现在界面中,而孤立页面将出现在Analytics(分析)和Search Console标签中的相应过滤器下方(执行抓取分析之后)。
3)切换到数据库存储模式
SEO Spider传统上使用RAM来存储数据,这使它能够快速,灵活地针对几乎所有机器规格进行爬网。但是,它对于爬网大型网站不是很可扩展。因此,去年年初我们推出了首个可配置的混合存储引擎,该引擎使SEO Spider能够以前所未有的规模针对任何桌面应用程序进行爬网,同时保留相同的熟悉的实时报告和可用性。
因此,如果您需要使用桌面搜寻器来搜寻数百万个URL,您确实可以。您也不需要继续增加RAM即可,而改用数据库存储。用户可以通过在界面中选择“数据库存储模式”来选择保存到磁盘(通过“配置”>“系统”>“存储”)。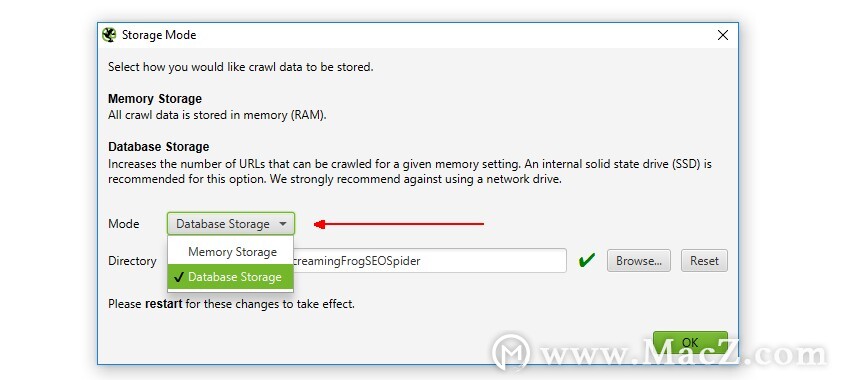
数据库存储石
这意味着SEO Spider将在RAM中保存尽可能多的数据(取决于用户分配),并将其余数据存储到磁盘。实际上,对于所有使用SSD(或速度更快的驱动器)的用户,我们都建议将其作为默认设置,因为它既快速又使用更少的RAM。
4)检索后请求Google Analytics(分析),Search Console和链接数据
如果您已经执行了爬网,却忘记了连接到Google Analytics(分析),Search Console或外部链接指标提供商,那么就不用担心了。您可以在抓取后连接到其中任何一个,然后单击“ API”选项卡底部漂亮隐藏的“请求API数据”按钮。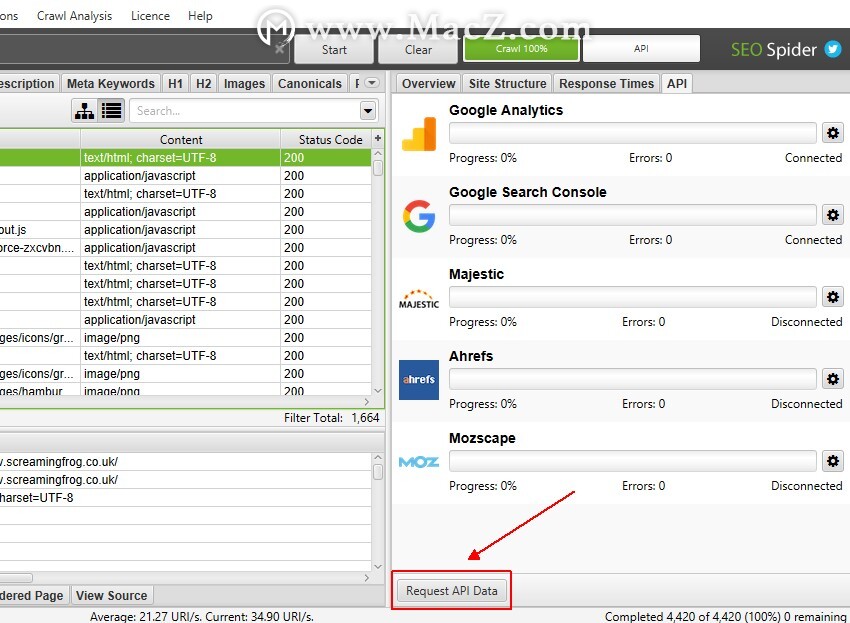
或者,也可以在“配置> API访问”主菜单中使用“请求API数据”。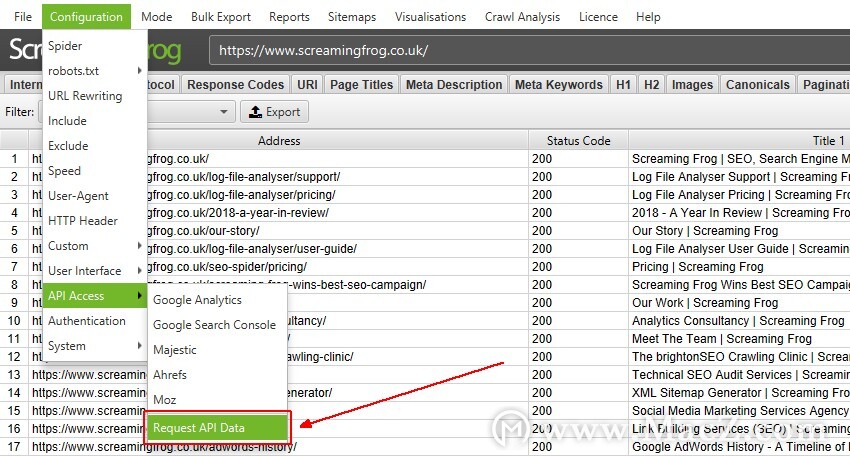
这意味着将数据从相应的API中提取出来,并与已经抓取的URL进行匹配。
5)禁用HSTS以查看“真实”重定向状态代码
HTTP严格传输安全性(HSTS)是一种标准,Web服务器可以通过该标准向客户端声明只能通过HTTps访问它。默认情况下,SEO Spider将遵循HSTS,如果在爬网过程中由服务器声明并发现内部HTTP链接,系统将报告状态为307的状态代码,其状态为“ HSTS策略”,重定向类型为“ HSTS策略”。报告HSTS设置在审核安全性时非常有用,307响应代码提供了一种发现不安全链接的简便方法。
与通常的重定向不同,此重定向实际上不是由Web服务器发送的,它是在内部(通过浏览器和SEO Spider)翻转的,它仅请求HTTps版本而不是HTTP URL(因为所有请求都必须为HTTps)。但是,报告的状态码为307,因为您必须为HSTS设置到期时间。这就是为什么它是一个临时重定向。
尽管HSTS声明所有请求都应通过HTTps进行,但仍然需要站点范围的HTTP-> HTTps重定向。这是因为除非通过HTTps发送,否则将忽略Strict-Transport-Security标头。因此,如果第一次访问您的站点不是通过HTTps,您仍然需要将该初始重定向到HTTps来传递Strict-Transport-Security标头。
因此,如果您要审核已启用HSTS的HTTP到HTTps迁移,则需要检查就位的基础“真实”站点范围重定向状态代码(并确定它是否为301重定向)。因此,您可以通过取消选中SEO Spider的“配置>蜘蛛>高级”下的“尊重HSTS策略”配置来选择禁用HSTS策略。
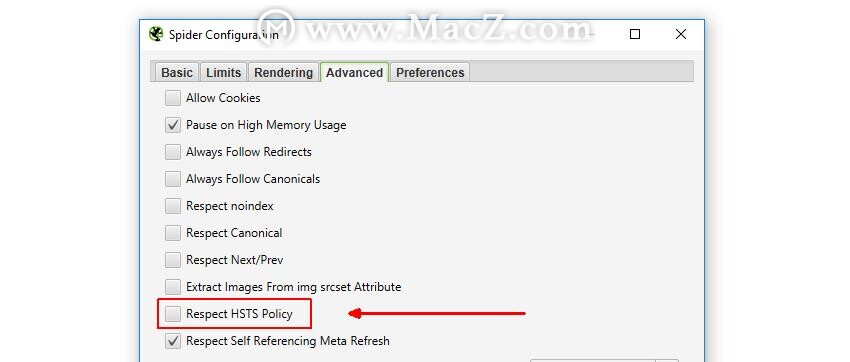
这意味着SEO Spider将完全忽略HSTS并报告底层的重定向和状态代码。当您知道所有HSTS设置正确后,您可以切换回尊重HSTS,而SEO Spider只会再次请求URL的安全版本。查阅我们的SEO指南以搜寻HSTS。
6)同时比较并运行抓取
目前,您无法直接在SEO Spider中比较抓取。但是,您可以打开软件的多个实例,并运行多个爬网,或同时比较爬网。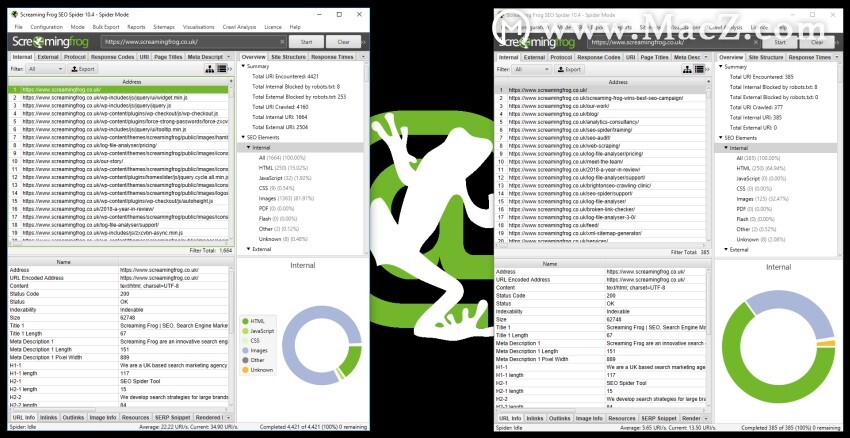
在Windows上,这就像通过快捷方式再次打开软件一样简单。对于macOS,要打开SEO Spider的其他实例,请打开终端并输入以下命令:
打开-n / Applications / Screaming \ Frog \ SEO \ Spider.app/
现在,您可以执行多个爬网,或同时比较多个爬网。
7)抓取任何Web表单,登录区域和旁路Bot保护
SEO Spider长期以来一直支持基于基本和摘要标准的身份验证,通常用于安全访问开发服务器和登台站点。但是,SEO Spider还可以使用其内置的Chromium浏览器登录到任何需要Cookie的Web表单。
可以在“配置>身份验证>基于表单”下找到此精美功能,您可以在其中加载几乎所有受密码保护的网站,Intranet或Web应用程序,并进行登录和爬网。例如,如果您确实想破坏(或改善)您的团队,则可以登录并爬上您宝贵的幻想足球。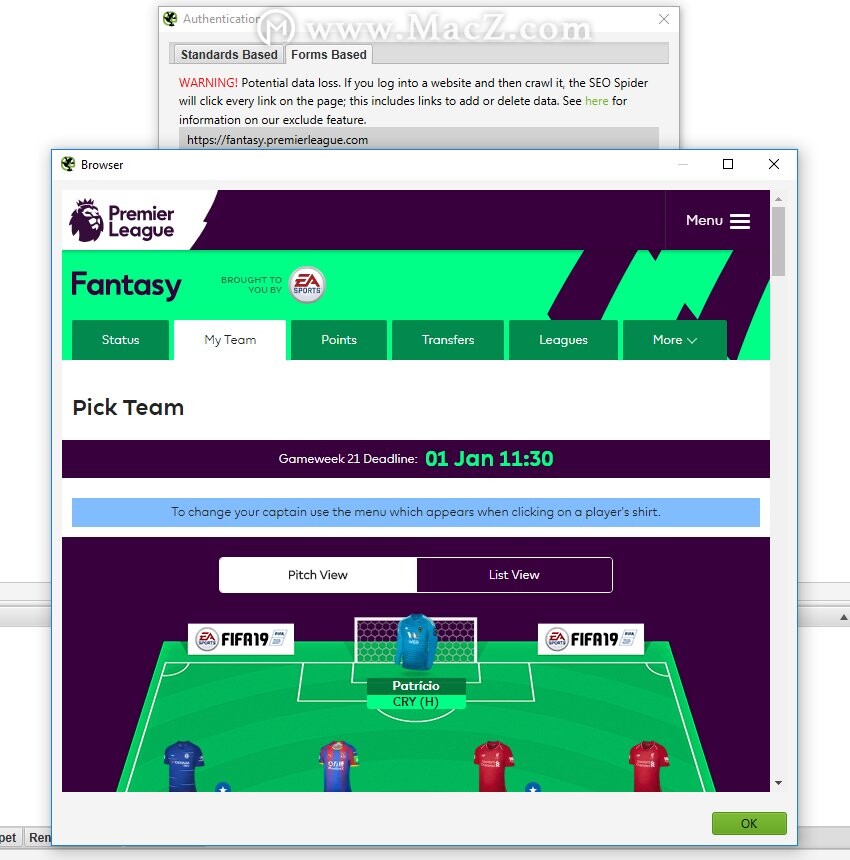
此功能非常强大,因为它提供了一种在SEO Spider中设置cookie的方法,因此它还可以用于诸如绕过geo IP重定向或站点使用带有reCAPTCHA的僵尸保护之类的情况。
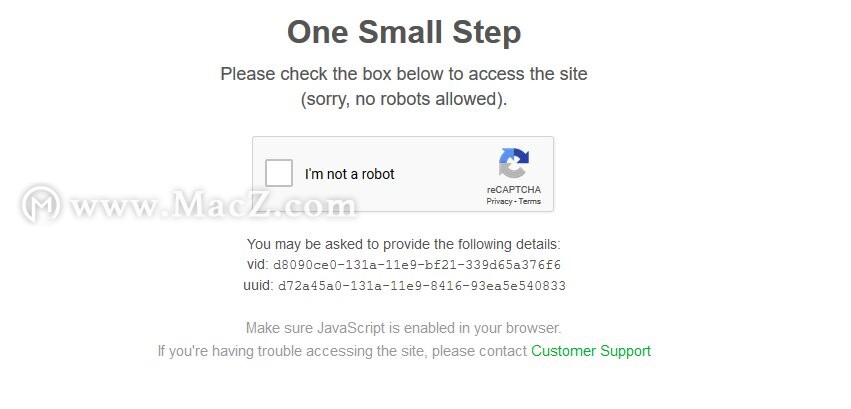
您可以仅将页面加载到内置浏览器中,确认您不是机器人,然后爬网。如果您在最初进行预抓取时加载页面,则可能甚至看不到验证码,并且会向其发送所需的Cookie。显然,您也应该获得该网站的许可。
但是,强大的功能会负责任地发挥作用,因此请谨慎使用此功能。
在测试过程中,以“管理员”身份登录时,我们让SEO Spider在我们的测试站点上松了下来,很有趣。我们让它爬行了半个小时;当时,它为该网站安装并设置了新主题,安装了108个插件并激活了其中的8个,删除了一些帖子,并且通常情况一团糟。
考虑到这一点,请阅读我们负责任地检索受密码保护的网站的指南。
8)使用JavaScript呈现模式抓取(和删除)URL片段
(请注意–下述行为已更改。默认情况下,在任何模式下都不对片段进行爬网。要爬网片段(无论模式如何),请通过“配置>蜘蛛>高级”启用“爬网片段标识符”)
有时,在审核网站时,使用带有片段(/页面名称/#this-is-a-fragment)的URL进行爬网很有用,并且默认情况下,SEO Spider将以JavaScript呈现模式对它们进行爬网。
您可以在下面查看使用它们的常见问题解答。
尽管这可能有所帮助,但搜索引擎显然会忽略该片段中的任何内容,并在没有该片段的情况下对URL进行爬网和索引。因此,通常您可能希望使用URL重写中的“正则表达式替换”功能来切换此行为。只需在提交的“正则表达式”中包含#。*,并将“替换”字段保留为空白即可。
这意味着它们将以与默认的纯HTML文本模式相同的方式进行爬网和索引而不会产生碎片。
9)利用“爬网分析”获得链接得分,更多数据(和数据洞察)
尽管上面讨论的某些功能已经有一段时间可用了,但``爬网分析''功能是在9月底(2018年)的10版中发布的。
SEO Spider在运行时分析和报告数据,在爬网过程中会填充指标,选项卡和过滤器。但是,作为内部PageRank计算的“链接分数”和少量过滤器需要在爬网结束时(或至少在爬网已暂停的情况下)进行计算。
需要“抓取分析”的13个项目的完整列表可以在SEO Spider顶级菜单的“抓取分析>配置”下看到,并在下面查看。
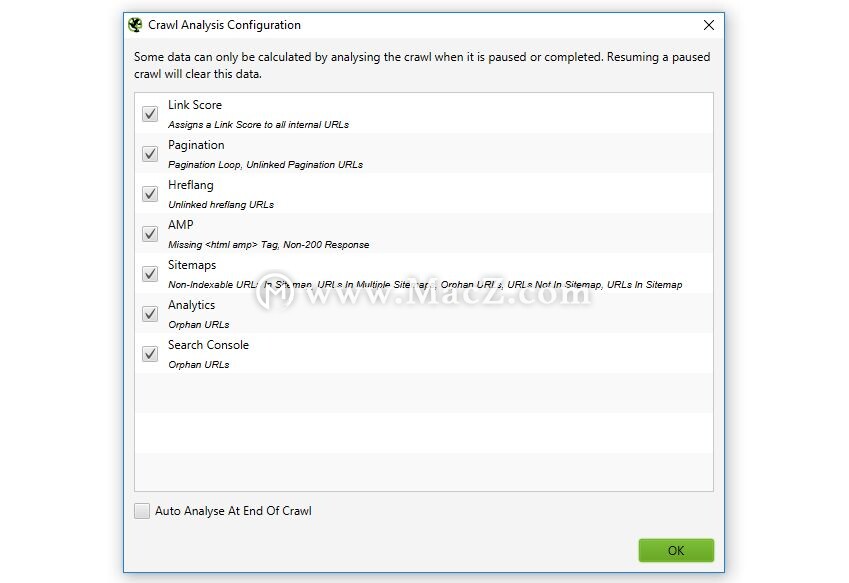
以上所有内容均为各自标签下的过滤器,“链接得分”是一种指标,在“内部”标签中显示为一列。
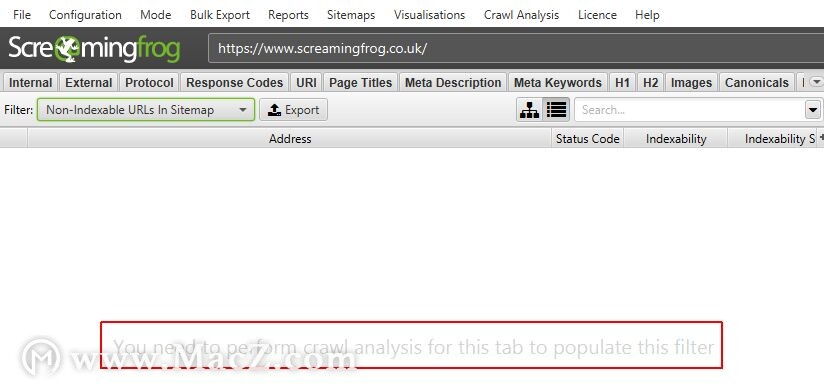
在右侧的“概述”窗口窗格中,需要进行“爬网分析”的过滤器标有“需要进行爬网分析”,以进一步说明。特别是“站点地图”过滤器,大多数情况下需要进行抓取后分析。
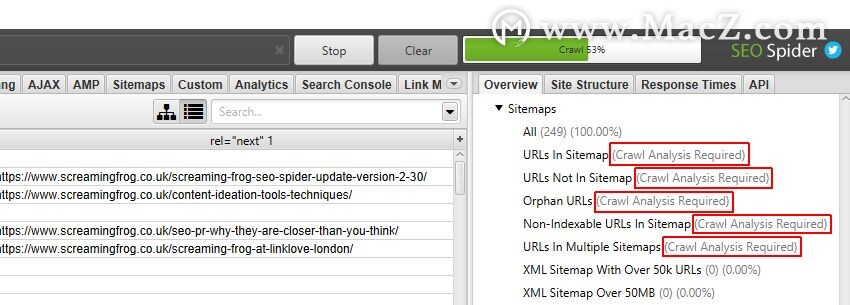
它们在主窗口窗格中也标记为“您需要对此选项卡执行爬网分析才能填充此过滤器”。
通过在“配置”下的相应“在爬网结束时自动分析”复选框打勾,可以在爬网结束时自动执行此分析,也可以由用户手动运行。
要运行爬网分析,只需单击“爬网分析>开始”。

抓取分析运行时,您会看到“分析”进度条,其中包含完成百分比。在此期间,SEO Spider可以继续正常使用。

爬网分析完成后,标有“需要进行爬网分析”的空过滤器将填充许多可爱的有见地的数据。
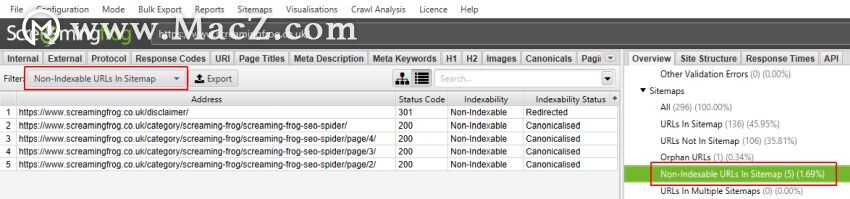
“链接得分”指标显示在“内部”标签中,并根据其内部链接计算页面的相对值。
为了简单起见,这使用从最小到最大的相对0-100点比例,这使您可以确定在哪些地方可以改进关键页面的内部链接。当使用其他内部链接数据(例如,链接数,唯一链接数和到页面的链接百分比(从整个网站))时,它可能特别强大。
10)保存HTML和渲染的HTML以帮助调试
我们偶尔会收到用户的支持查询,报告说缺少页面标题,描述,规范或页面内容,这些内容似乎没有被SEO Spider所获取,但可以在浏览器中以及查看HTML源代码时看到。
通常,这被认为是某种错误,但是大多数情况下,它取决于用户代理,accept-language标头,是否响应浏览器而不是SEO Spider的请求。 cookie被接受,或者如果服务器处于负载状态(例如)。
因此,进行自我诊断和调查的一种简单方法是,通过选择将服务器返回的HTML保存在响应中,来确切地看到SEO Spider可以看到的内容。
通过导航到“配置>蜘蛛>高级”,您可以选择存储原始HTML和渲染的HTML来检查DOM(在JavaScript渲染模式下)。
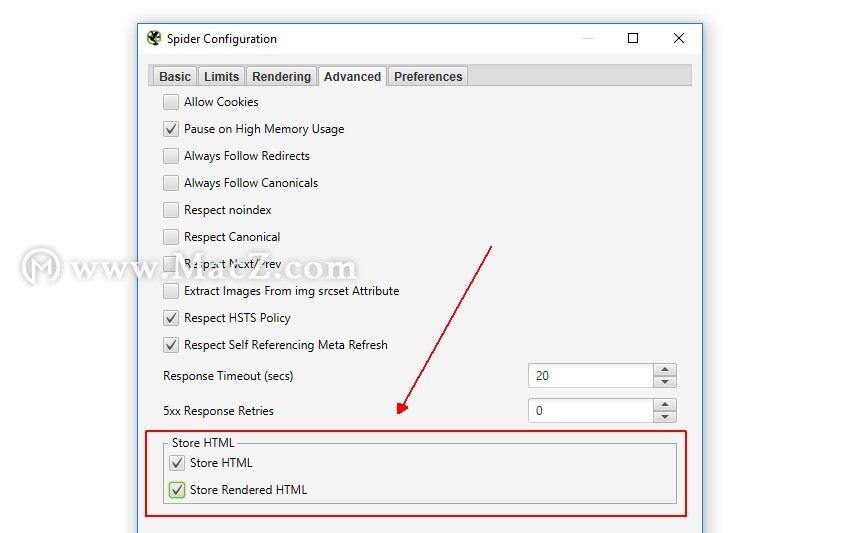
检索到URL后,可以在下部窗口的“查看源代码”选项卡中查看返回到SEO Spider检索页面时的确切HTML。
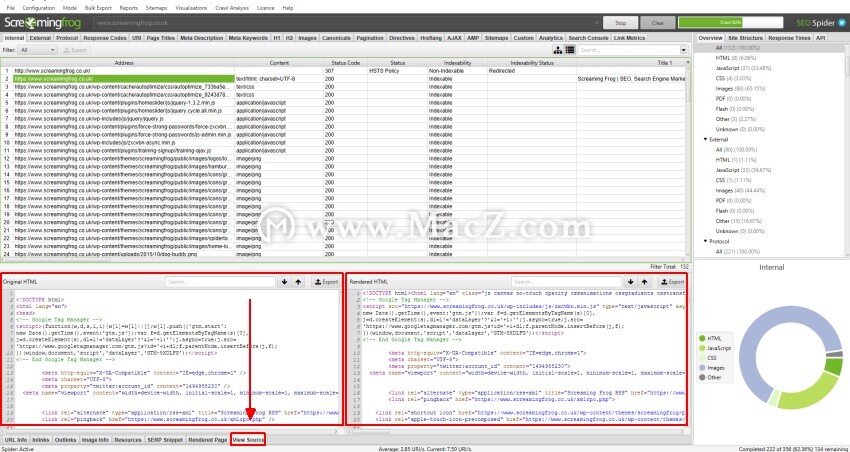
通过查看返回的HTML,您可以调试问题,然后使用其他用户代理进行调整,或者接受Cookie等。例如,您将看到缺少的页面标题,然后能够确定其丢失的条件。
此功能是一种非常有效的方法,可以快速诊断问题,并更好地了解SEO Spider能够看到和抓取的内容。
11)通过CLI使用保存的配置文件
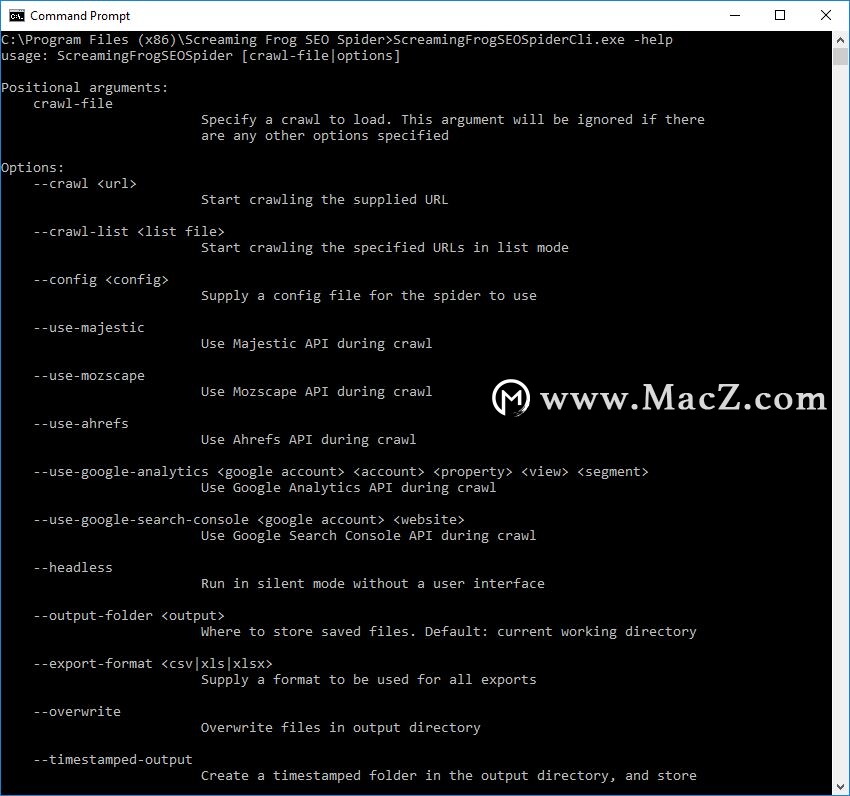
在最新的SEO Spider版本10中,我们引入了命令行界面。SEO Spider可以通过命令行进行操作,包括启动,保存和导出,并且您可以使用–help查看可用的完整参数。
但是,并非所有配置选项都可用,因为如果您考虑全部可用,则会有数百个参数。因此,诀窍是将保存的配置文件用于更高级的方案。
打开SEO Spider GUI,选择您的选项,无论是基本配置还是自定义搜索,提取等更高级的功能,然后保存配置文件。
要保存配置文件,请单击“文件>另存为”并调整文件名(最好是描述性的!)。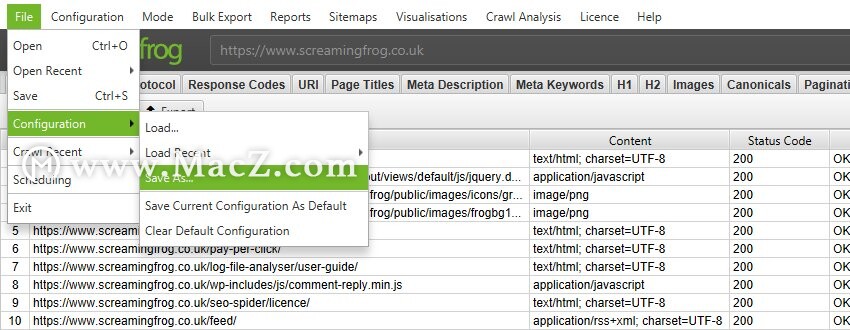
然后,您可以提供config参数来设置命令行爬网的配置配置文件(并在将来使用)。
--config“ C:\ Users \您的名称\ Crawls \ super-awesome.seospiderconfig”
这确实打开了通过命令行使用SEO Spider的可能性。
以上就是今天为大家介绍的“Screaming Frog SEO Spider的11个鲜为人知的功能你用过几个?”希望对您有所帮助。