
Screaming Frog Log File Analyser for Mac(尖叫青蛙网络爬虫软件) v5.3激活版




Screaming Frog Log File Analyser for Mac(尖叫青蛙网络爬虫软件) v5.3激活版
Screaming Frog Log File AnalyserMac破解版可以帮助您从不同的网页上选择需要抓取的内容,可以抓取网站的网址,并且可以实时分析结果,还会收集关键性的现场数据,便于SEO做出正确的决策,即使是无法响应的网页也可以,绝对是检测网站和搜索网络资源的神器!
Screaming Frog SEO Spider for Mac软件介绍
Screaming Frog SEO Spider for Mac是一个网站爬虫,允许你抓取网站的网址,并获取关键要素,分析和审计技术和现场搜索引擎优化。
Screaming Frog SEO Spider for Mac安装教程
镜像包下载完毕后打开,拖动到右边的应用程序进行安装
下面是Screaming Frog Log File Analyser软件详细的注册激活教程
打开Screaming Frog Log File Analyser,在顶部菜单栏打开licence,然后点击【enter licence】
弹出seo spider mac版注册界面,留着待用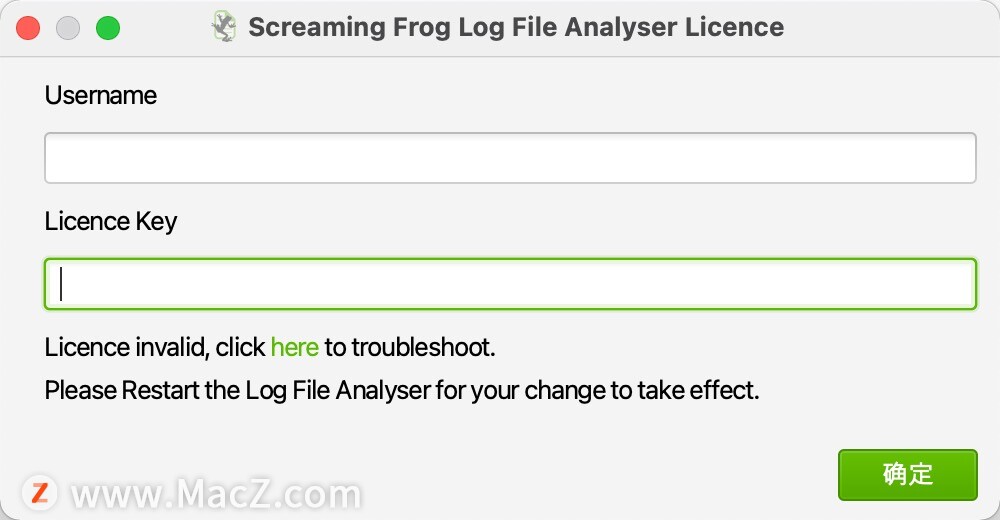
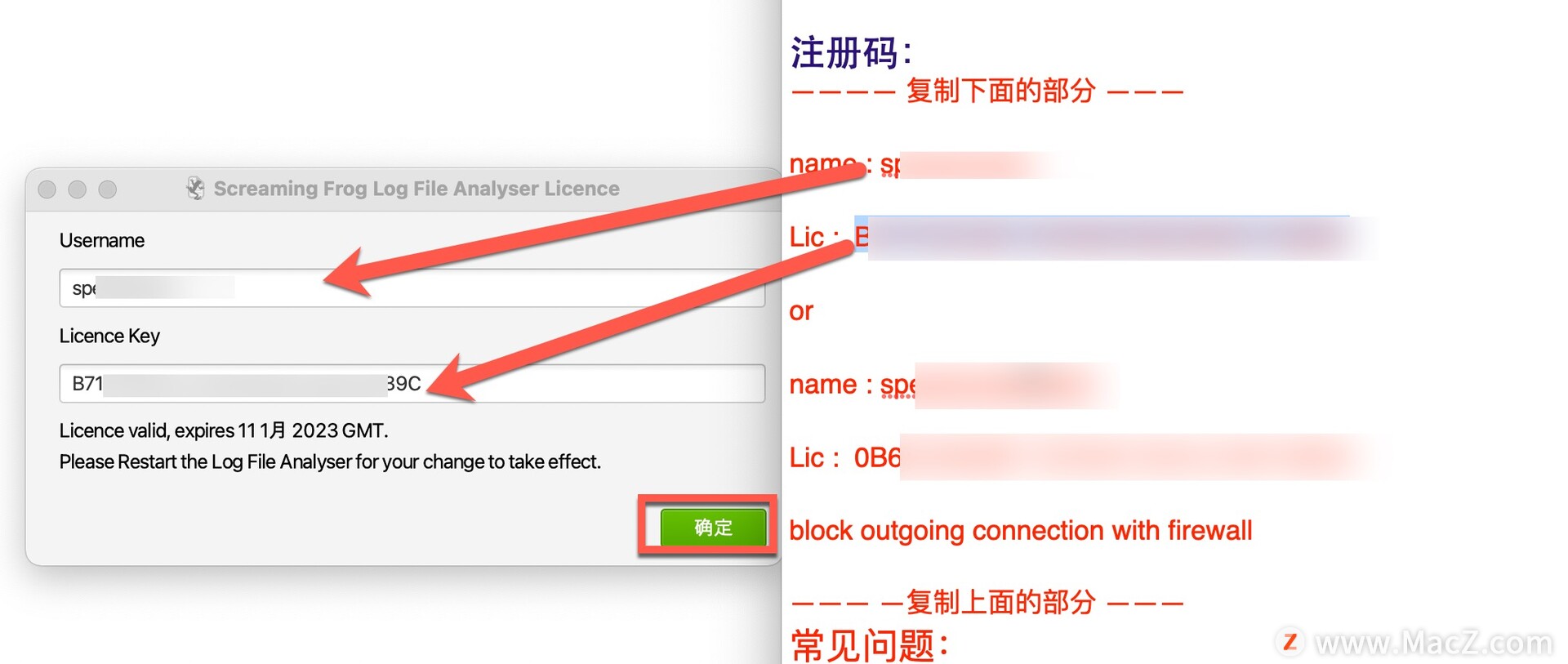
返回镜像包打开【Screaming Frog Log File Analyser注册码】

将注册码复制粘贴到SEO Spider注册界面,然后点击确定:
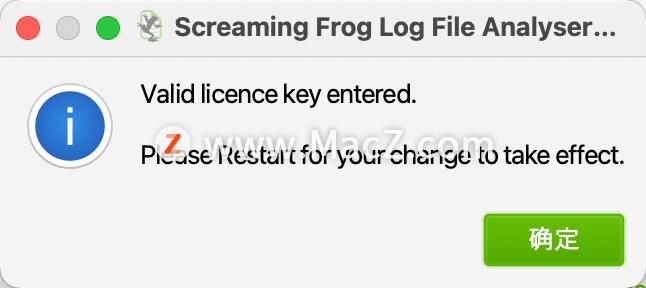
提示输入有效的许可证密钥。请重新启动以使您的更改生效,重新启动,Screaming Frog Log File Analyser注册成功!!
Screaming Frog Log File Analyser for Mac功能特色
1、找到断开的链接
立即抓取网站并找到损坏的链接(404s)和服务器错误。批量导出错误和源URL以进行修复,或发送给开发人员。
2、审核重定向
查找临时和永久重定向,识别重定向链和循环,或上传URL列表以在站点迁移中进行审核。
3、分析页面标题和元数据
在抓取过程中分析页面标题和元描述,并识别网站中过长,短缺,缺失或重复的内容。
4、发现重复内容
使用md5算法检查发现完全重复的URL,部分重复的元素(如页面标题,描述或标题)以及查找低内容页面。
5、使用XPath提取数据
使用CSS Path,XPath或regex从网页的HTML中收集任何数据。这可能包括社交元标记,其他标题,价格,SKU或更多!
6、审查机器人和指令
查看被robots.txt,元机器人或X-Robots-Tag指令阻止的网址,例如'noindex'或'nofollow',以及规范和rel =“next”和rel =“prev”。
7、生成XML站点地图
快速创建XML站点地图和图像XML站点地图,通过URL进行高级配置,包括上次修改,优先级和更改频率。
8、与Google Analytics集成
连接到Google AnalyticsAPI并针对抓取功能获取用户数据,例如会话或跳出率和转化次数,目标,交易和针对目标网页的收入。
9、抓取JavaScript网站
使用集成的Chromium WRS渲染网页,以抓取动态的,富含JavaScript的网站和框架,例如Angular,React和Vue.js.
10、可视化站点架构
使用交互式爬网和目录强制导向图和树形图站点可视化评估内部链接和URL结构。
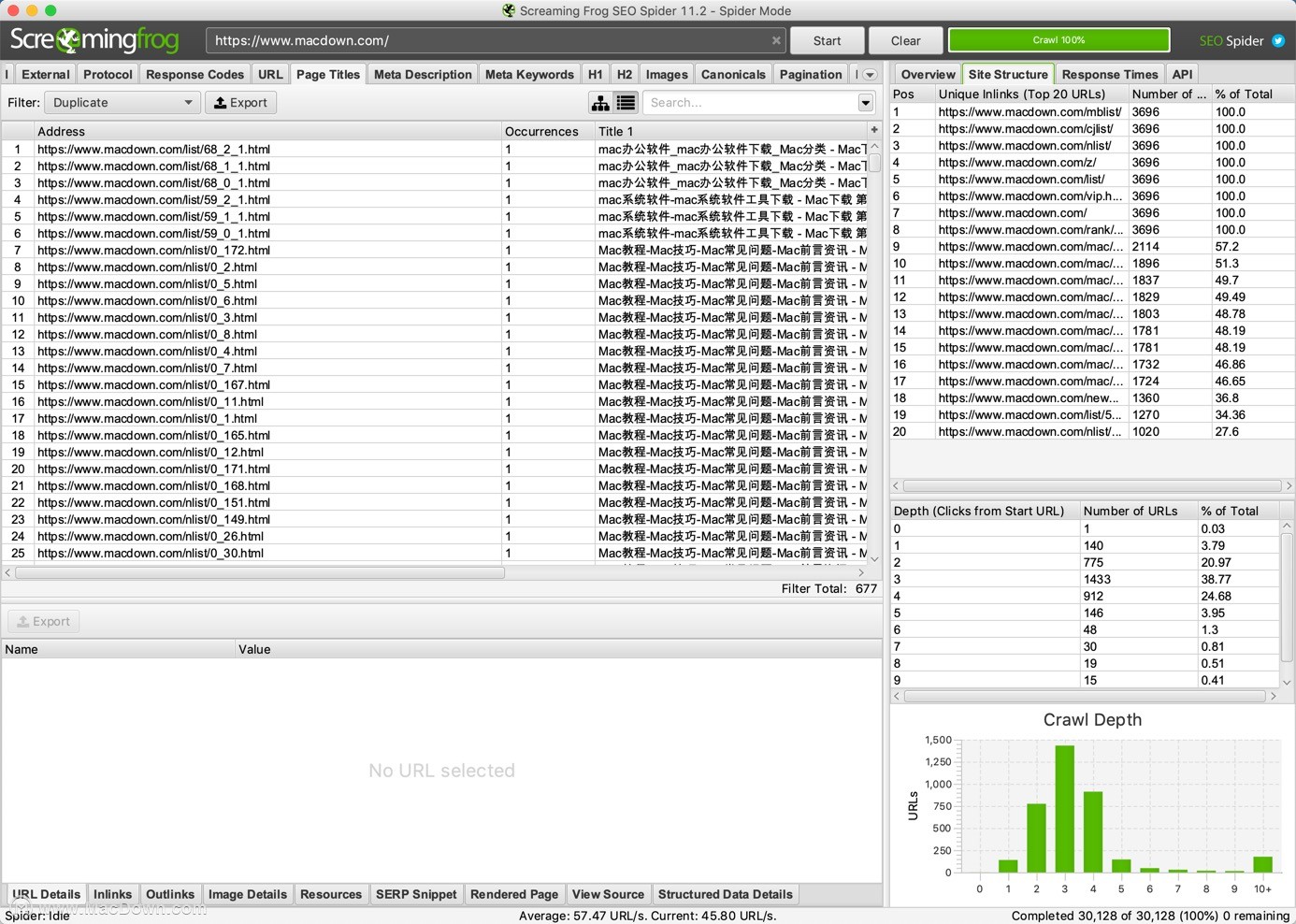
Screaming Frog SEO Spider for Mac快速摘要
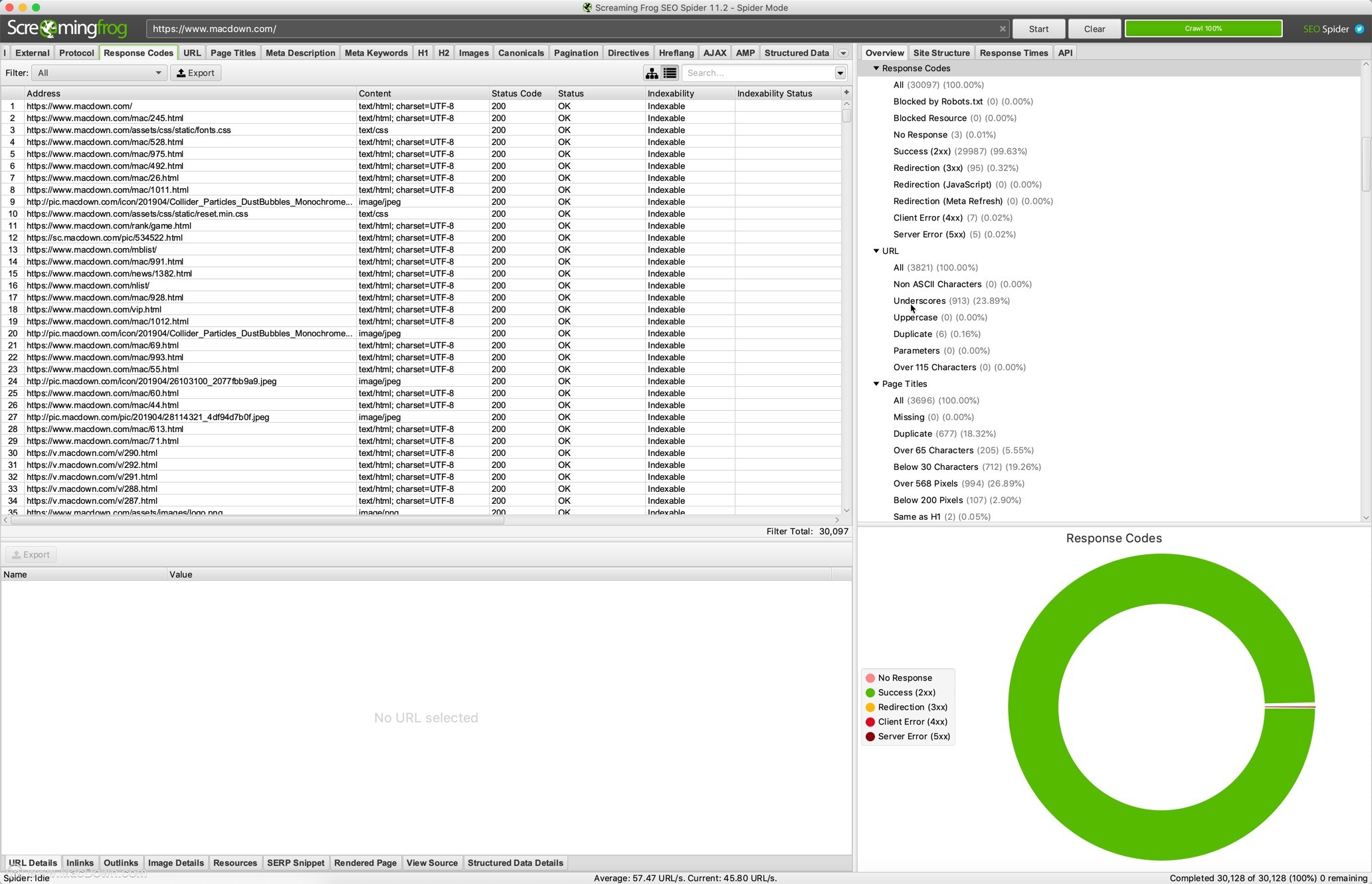
错误 - 客户端错误,例如链接断开和服务器错误(无响应,4XX,5XX)。
重定向 - 永久,临时重定向(3XX响应)和JS重定向。
阻止的网址 - robots.txt协议不允许查看和审核网址。
阻止的资源 - 在呈现模式下查看和审核被阻止的资源。
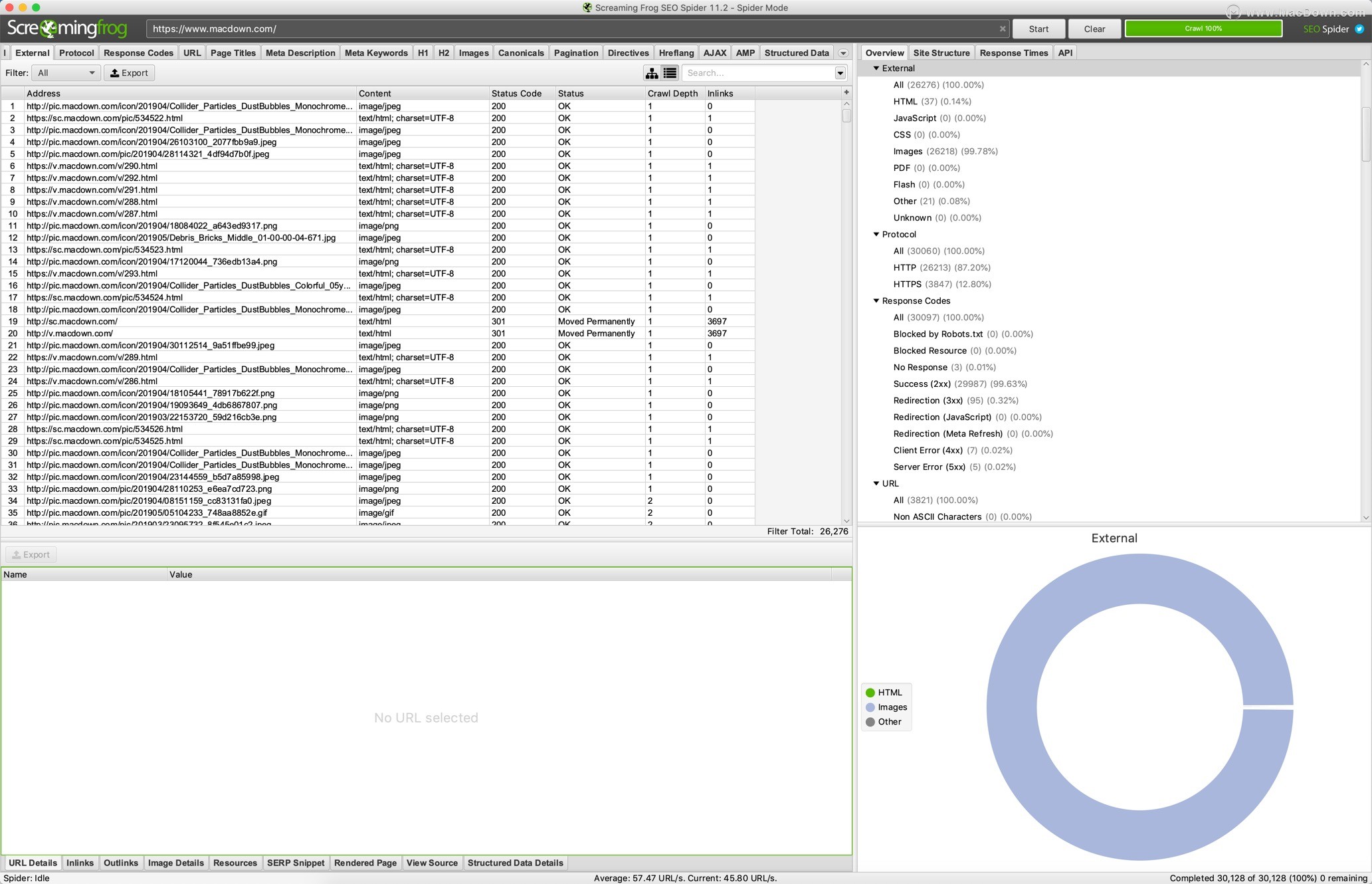
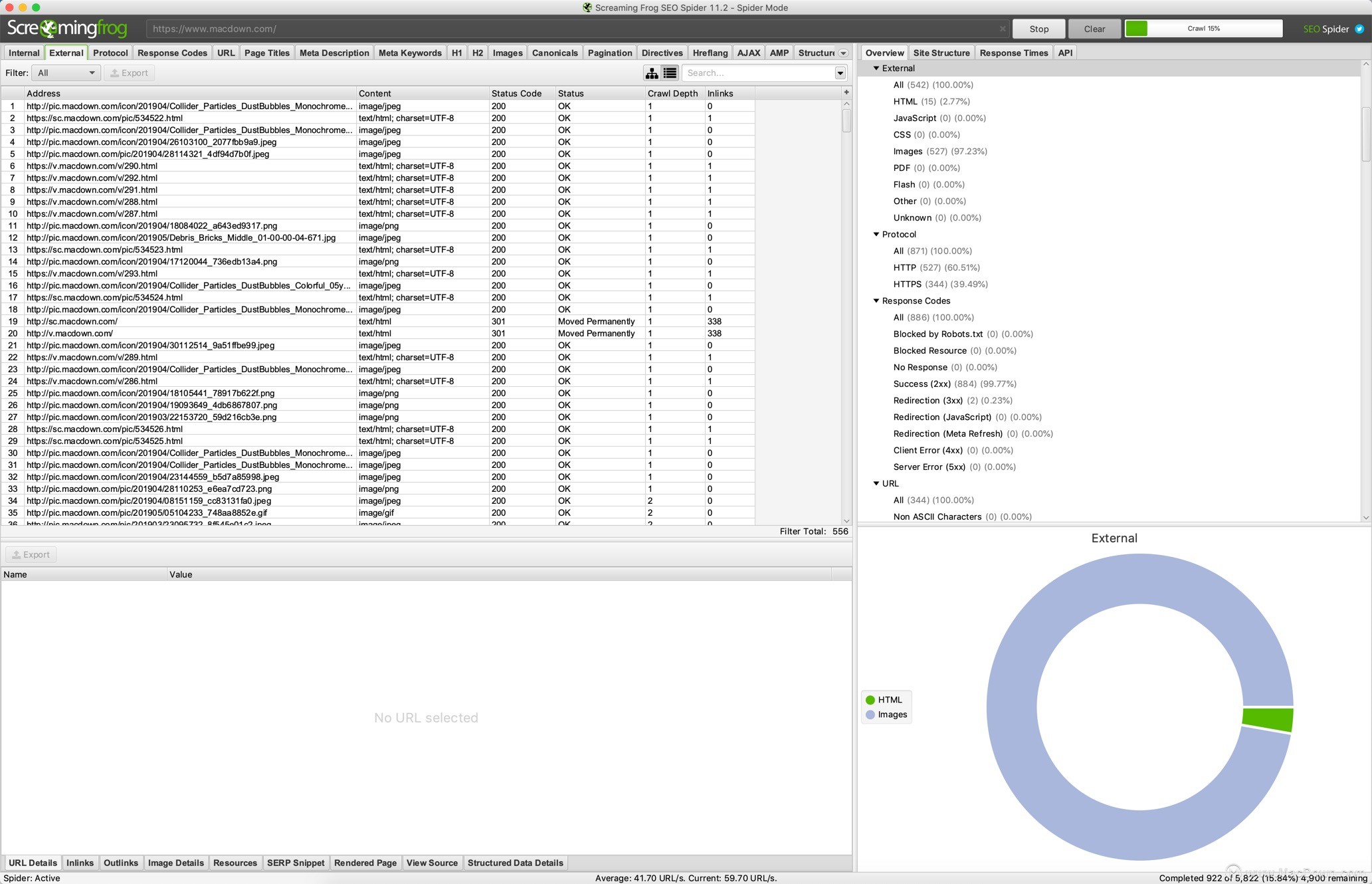
外部链接 - 所有外部链接及其状态代码。
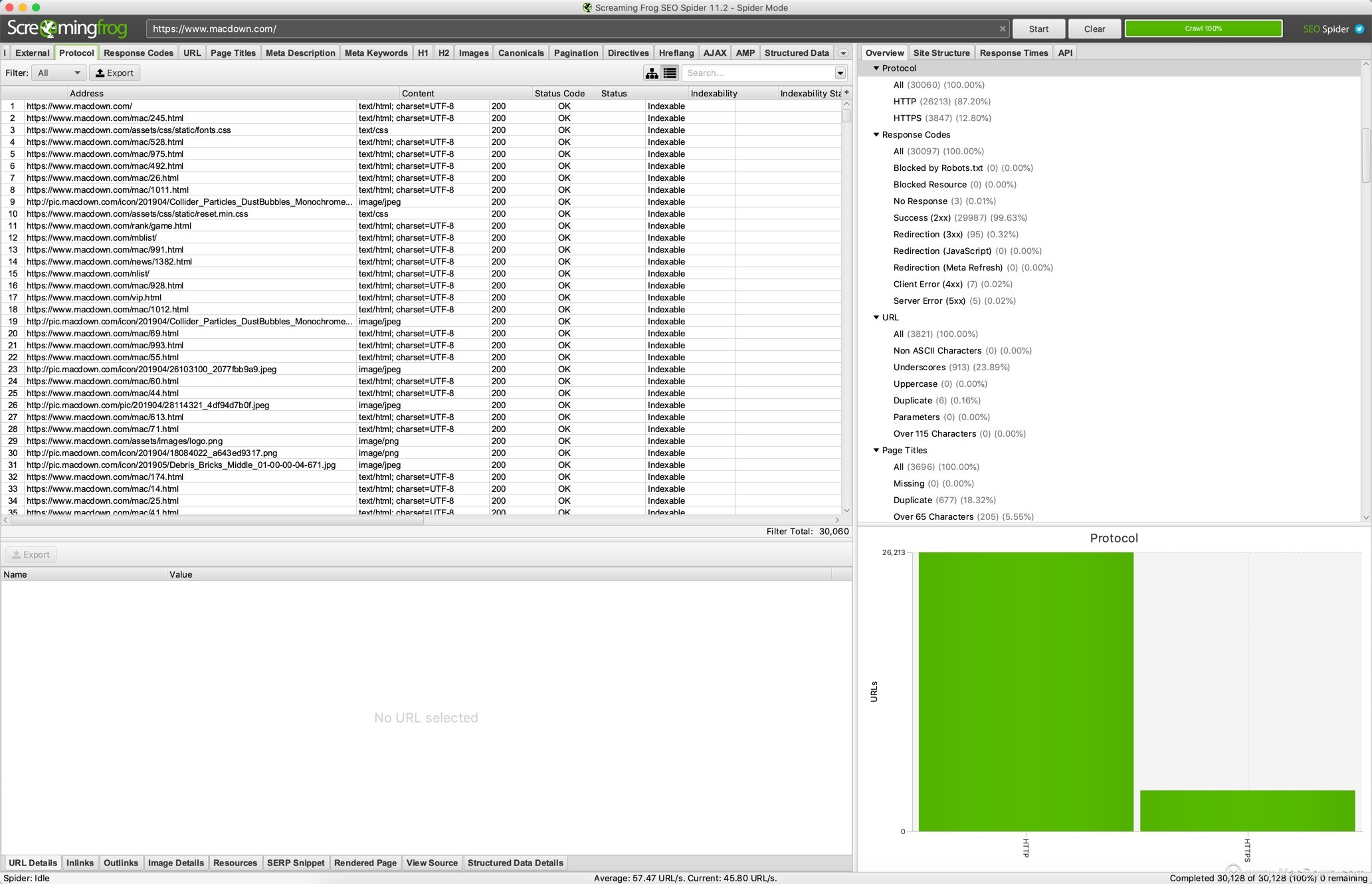
协议 - URL是安全的(HTTps)还是不安全的(HTTP)。
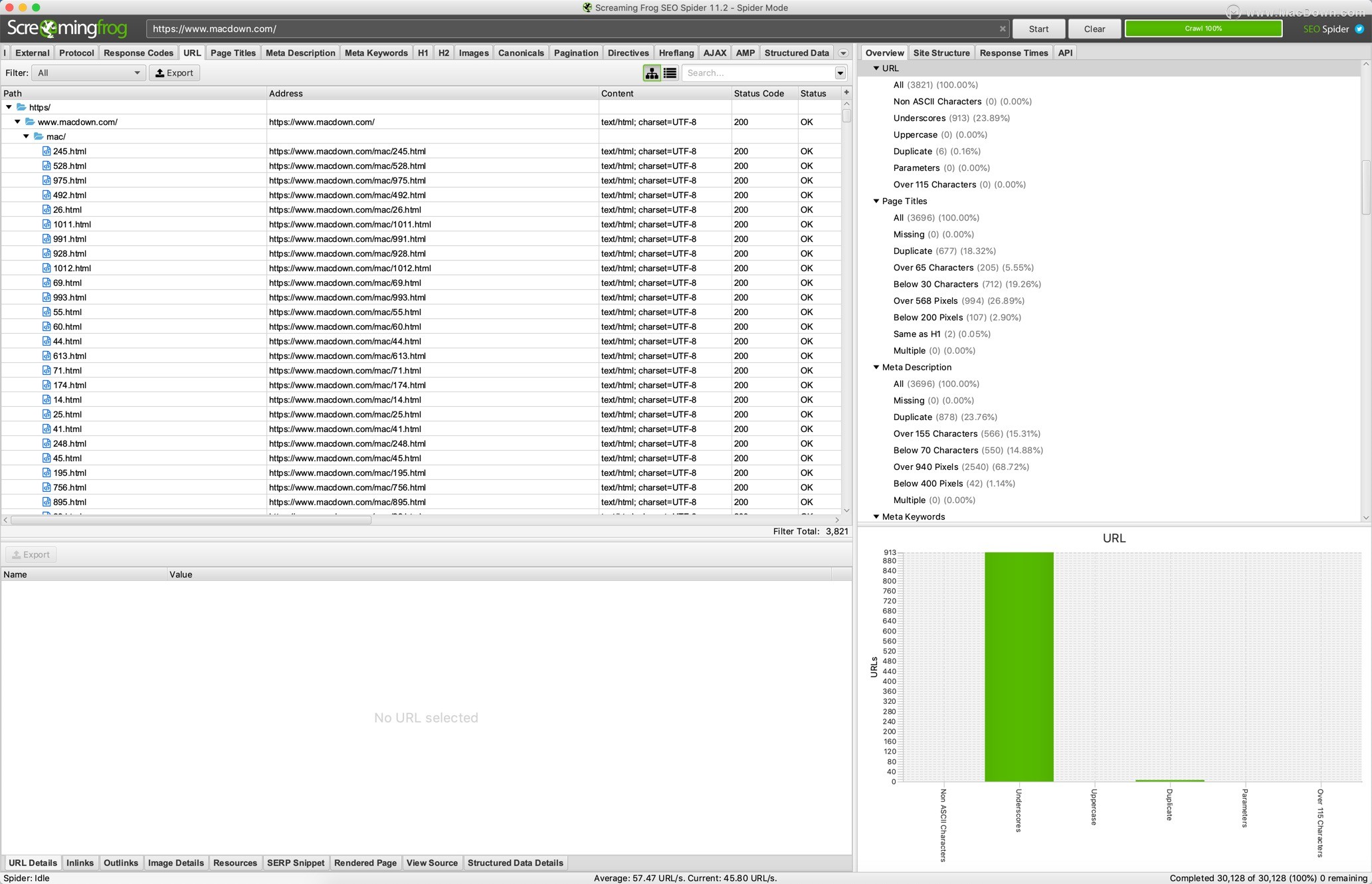
URI问题 - 非ASCII字符,下划线,大写字符,参数或长URL。
重复页面 - 哈希值/ MD5checksums算法检查完全重复的页面。
页面标题 - 缺失,重复,超过65个字符,短,像素宽度截断,与h1相同或多个。
元描述 - 缺失,重复,超过156个字符,短,像素宽度截断或多个。
元关键字 - 主要供参考,因为它们不被谷歌,必应或雅虎使用。
文件大小 - 网址和图片的大小。
响应时间。
最后修改的标题。
页面(抓取)深度。
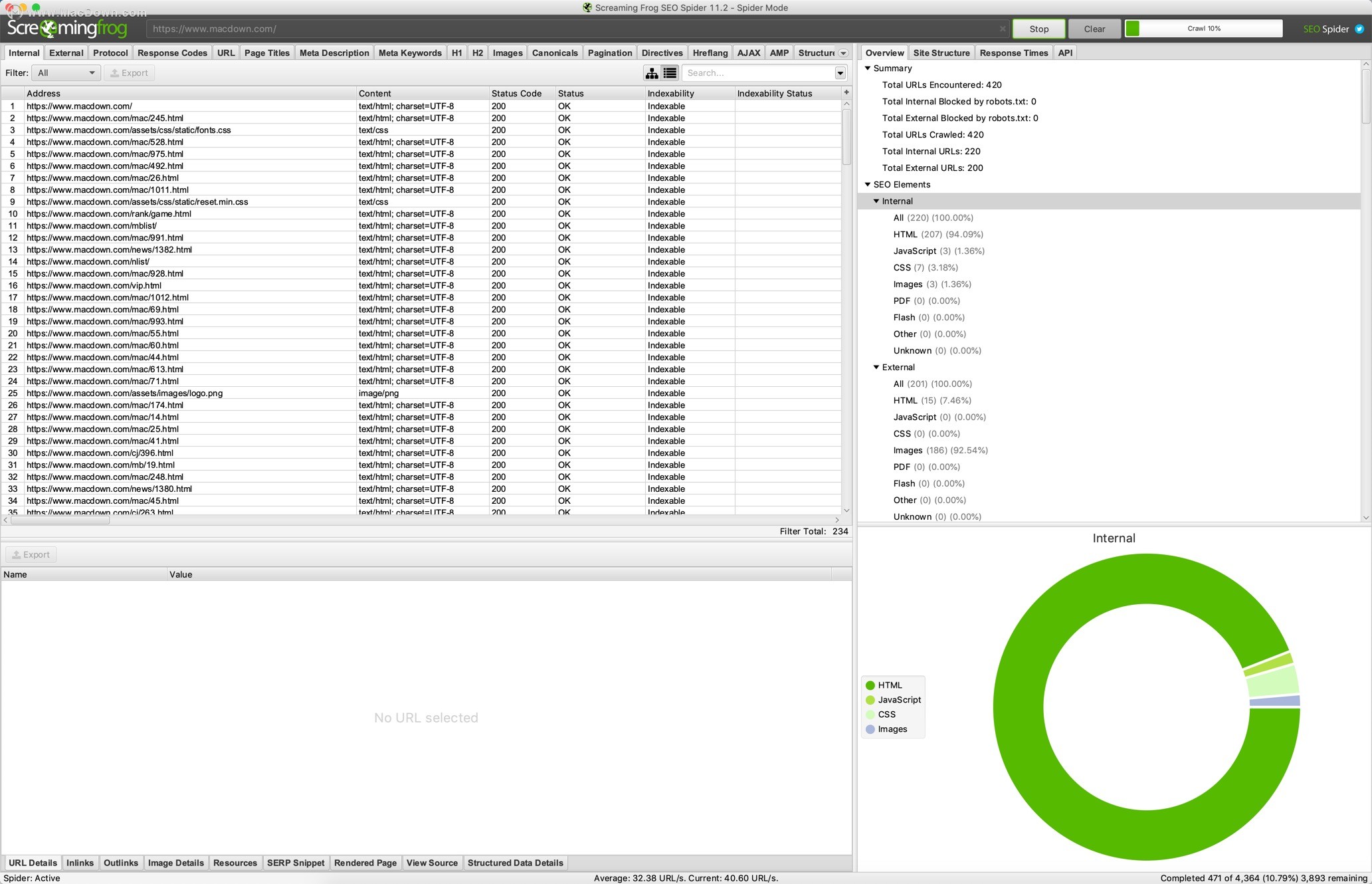
字数。
H1 - 缺失,重复,超过70个字符,多个。
H2 - 缺失,重复,超过70个字符,多个。
元机器人 - 索引,无索引,跟随,nofollow,noarchive,nosnippet,noodp,noydir等。
元刷新 - 包括目标页面和时间延迟。
规范链接元素和规范HTTP标头。
X-Robots-Tag中。
分页 - rel =“next”和rel =“prev”。
关注&Nofollow - 在页面和链接级别(真/假)。
重定向链 - 发现重定向链和循环。
hreflang属性 - 审核缺少的确认链接,不一致和不正确的语言代码,非规范的hreflang等。
AJAX - 选择遵守Google现已弃用的AJAX抓取方案。
渲染 - 通过在JavaScript执行后抓取渲染的HTML来抓取像AngularJS和React这样的JavaScript框架。
Inlinks - 链接到URI的所有页面。
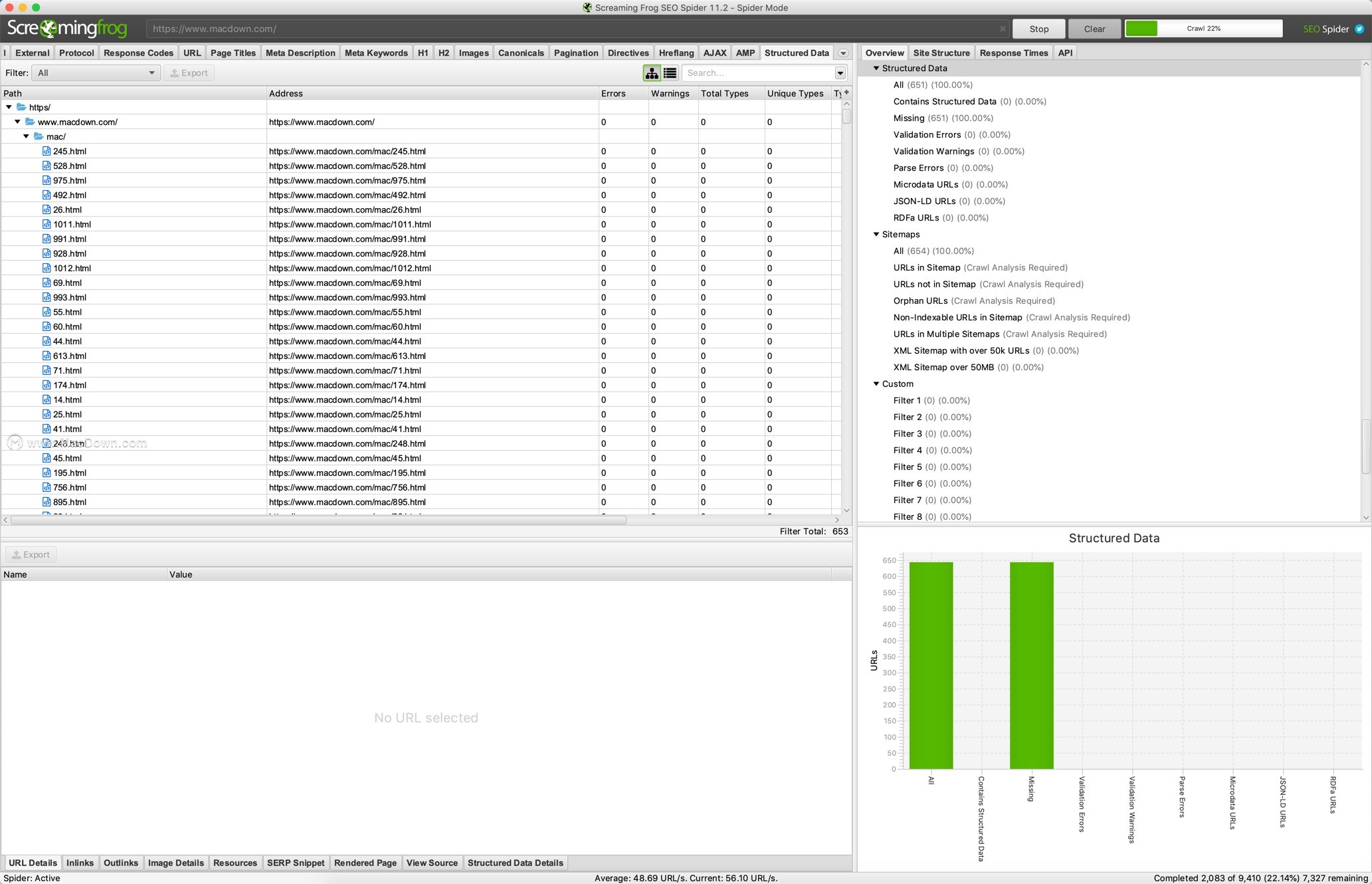
Outlinks - URI链接到的所有页面。
锚文本 - 所有链接文本。从带有链接的图像中替换文本。
图像 - 具有图像链接的所有URI和来自给定页面的所有图像。图像超过100kb,缺少替代文字,替代文字超过100个字符。
用户代理切换器 - 抓取Googlebot,Bingbot,Yahoo!Slurp,移动用户代理或您自己的自定义UA。
自定义HTTP标头 - 在请求中提供任何标头值,从Accept-Language到cookie。
自定义源代码搜索 - 在网站的源代码中找到您想要的任何内容!无论是谷歌分析代码,特定文本还是代码等。
自定义提取 - 使用XPath,CSS路径选择器或正则表达式从URL的HTML中删除任何数据。
Google Analytics集成 - 连接到Google AnalyticsAPI并在抓取过程中直接提取用户和转化数据。
Google Search Console集成 - 连接到Google Search Analytics API并针对网址收集展示次数,点击次数和平均排名数据。
外部链接度量标准 - 将Majestic,Ahrefs和Moz API中的外部链接指标拖入爬行以执行内容审核或配置文件链接。
XML站点地图生成 - 使用SEO蜘蛛创建XML站点地图和图像站点地图。
自定义robots.txt - 使用新的自定义robots.txt下载,编辑和测试网站的robots.txt。
渲染的屏幕截图 - 获取,查看和分析已爬网的渲染页面。
存储和查看HTML和呈现的HTML - 分析DOM的必要条件。
AMP抓取和验证 - 使用官方集成的AMP Validator抓取AMP网址并对其进行验证。
XML站点地图分析 - 单独爬网XML站点地图或爬行的一部分,以查找丢失的,不可索引的和孤立的页面。
可视化 - 使用爬网和目录树强制导向图和树图分析网站的内部链接和URL结构。
结构化数据和验证 - 根据Schema.org规范和Google搜索功能提取和验证结构化数据。
更新日志
修复数据库爬网减慢(爬行和保存时)。
修复SERP生成中的崩溃。
修复可索引分类错误。
修复自定义搜索,使其对“包含”和“不包含”不区分大小写。
修复每个会话GA指标的GA页面视图中的拼写错误。
将鼠标悬停在圆环图上时修复崩溃。